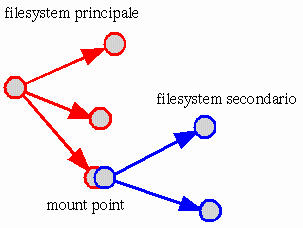
Figura 2.1: Collegamento di un filesystem secondario in corrispondenza di un punto di innesto (o mount point).
Il sistema operativo GNU/Linux č il risultato di una serie molto grande di apporti da diversi ambienti Unix. Quindi, gran parte di ciň che riguarda o compone GNU/Linux, non č esclusivo di questo ambiente.
Questo capitolo introduttivo č rivolto a tutti i lettori che non hanno avuto esperienze con Unix, ma anche chi ha giŕ una conoscenza di Unix farebbe bene a darci un'occhiata.
I sistemi operativi Unix, e quindi anche GNU/Linux, sono sensibili alla differenza tra le lettere maiuscole e minuscole. La differenza č sostanziale, per cui gli ipotetici file denominati: Ciao, cIao, CIAO, ecc. sono tutti diversi.
Non bisogna confondere questa caratteristica con quello che puň succedere in altri ambienti, come per esempio MS-Windows 95/98, che preservano l'indicazione delle lettere maiuscole o minuscole, ma che poi non fanno differenza quando si vuole fare riferimento a quei file.
Quando in un contesto si fa differenza tra maiuscole e minuscole, capita spesso di vederlo definito come case sensitive, e per converso, quando non si fa differenza, come case insensitive.
Negli ambienti Unix si fa spesso riferimento al termine root in vari contesti e con significati differenti. Root č la radice, o l'origine, e non significa niente altro. A seconda del contesto, ne rappresenta l'origine, o il punto iniziale. Per esempio, si puň avere:
una directory root, che č la directory principale di un filesystem, ovvero la directory radice;
un filesystem root, che č il filesystem principale di un gruppo che si unisce insieme;
un utente root, che č l'amministratore;
un dominio root, che č il dominio principale;
una finestra root che č quella principale, ovvero la superficie grafica (desktop) su cui si appoggiano le altre finestre del sistema grafico X.
Le situazioni in cui si presenta questa definizione possono essere molte di piů. L'importante, per ora, č avere chiara l'estensione del significato di questa parola.
GNU/Linux, come gli altri sistemi derivati da Unix, č multiutente. La multiutenza implica una distinzione tra i vari utenti. Fondamentalmente si distingue tra l'amministratore del sistema, o superuser, e gli altri utenti.
L'amministratore del sistema č quell'utente che puň fare tutto quello che vuole, soprattutto rischia di produrre gravi danni anche solo per piccole disattenzioni.
L'utente comune č quello che utilizza il sistema senza pretendere di organizzarlo e non gli č possibile avviare programmi o accedere a dati che non lo riguardano.
Per poter utilizzare un sistema di questo tipo, occorre essere stati registrati, ovvero, occorre avere ottenuto un account.
Dal punto di vista dell'utente, l'account č un nome abbinato a una password (una parola di accesso, o una parola d'ordine) che gli permette di essere riconosciuto e quindi di poter accedere. Oltre a questo, l'account stabilisce l'appartenenza a un gruppo di utenti.
|
Il nome dell'amministratore č sempre |
I sistemi Unix e i programmi che su questi sistemi possono essere utilizzati, non sono predisposti per un utilizzo distratto: gli ordini non vengono discussi. Molti piccoli errori possono essere disastrosi se sono compiuti dall'utente root.
Č molto importante evitare il piů possibile di utilizzare il sistema in qualitŕ di utente amministratore (root) anche quando si č l'unico utilizzatore del proprio elaboratore.
Il sistema operativo GNU/Linux, cosě come tutti i sistemi operativi Unix, č composto essenzialmente da:
un sistema di avvio o boot;
un kernel;
un filesystem;
un sistema di inizializzazione e gestione dei processi in esecuzione;
un sistema di gestione della rete;
un sistema di gestione delle stampe;
un sistema di registrazione e controllo degli accessi;
una shell (interprete dei comandi);
alcuni programmi di utilitŕ (utility) per la gestione del sistema;
strumenti di sviluppo software (C/C++).
Il boot č il modo con cui un sistema operativo puň essere avviato quando l'elaboratore viene acceso. Di solito, il software registrato su ROM degli elaboratori basati sull'uso di dischi, č fatto in modo da eseguire le istruzioni contenute nel primo settore di un dischetto, oppure, in sua mancanza, del cosiddetto MBR (Master Boot Record) che č il primo settore del primo disco fisso. Il codice contenuto nel settore di avvio di un dischetto o del disco fisso, provvede all'esecuzione del kernel (lo avvia).
Con GNU/Linux installato in un elaboratore i386, la configurazione e la gestione del sistema di avvio viene fatta principalmente attraverso due modi possibili:
LILO, che č in grado di predisporre un settore di avvio su un dischetto, sull'MBR o sul primo settore della partizione contenente GNU/Linux;
Loadlin, che permette di avviare l'esecuzione di un kernel Linux da una sessione Dos.
Il kernel, come suggerisce il nome, č il nocciolo del sistema operativo. I programmi utilizzano il kernel per le loro attivitŕ, e in questa maniera sono sollevati dall'agire direttamente con la CPU. Di solito, č costituito da un file unico, il cui nome potrebbe essere vmlinuz (oppure zImage, bzImage e altri), ma puň comprendere anche moduli aggiuntivi, per la gestione di componenti hardware specifici che devono poter essere attivati e disattivati durante il funzionamento del sistema.
Quando il kernel viene avviato (attraverso il sistema di avvio), esegue una serie di controlli diagnostici in base ai tipi di dispositivi (componenti hardware) per il quale č stato predisposto, quindi monta (mount) il filesystem principale (root), e infine avvia la procedura di inizializzazione del sistema (Init).
Il filesystem č il modo con cui sono organizzati i dati all'interno di un disco o di una sua partizione. Nei sistemi operativi Unix non esiste la possibilitŕ di distinguere tra un'unitŕ di memorizzazione e un altra, come avviene nel Dos, in cui ogni disco o partizione sono contrassegnati da una lettera dell'alfabeto (A:, B:, C:). Nei sistemi Unix, tutti i filesystem cui si vuole poter accedere devono essere concatenati assieme, in modo da formare un unico filesystem globale.
Quando un sistema Unix viene avviato, si attiva il filesystem principale, o root, e quindi possono essere collegati a questo altri filesystem a partire da una directory o sottodirectory di quella principale. Dal momento che per accedere ai dati di un filesystem diverso da quello principale occorre che questo sia collegato, nello stesso modo, per poter rimuovere l'unitŕ di memorizzazione contenente questo filesystem, occorre interrompere questo collegamento. Ciň significa che, nei sistemi Unix, non si puň inserire un dischetto, accedervi immediatamente e toglierlo quando si vuole: occorre dire al sistema di collegare il filesystem del dischetto, quindi lo si puň usare come parte dell'unico filesystem globale. Al termine si deve interrompere questo collegamento e solo allora si puň rimuovere il dischetto.
Figura 2.1:
Collegamento di un filesystem secondario in corrispondenza di un punto di innesto (o mount point).
L'operazione con cui si collega un filesystem secondario nel filesystem globale viene detta mount, e normalmente si utilizza il verbo montare con questo significato; l'operazione inversa viene detta unmount e conseguentemente si utilizza il verbo smontare. La directory a partire dalla quale si inserisce un altro filesystem č il mount point, e potrebbe essere definito come il punto di innesto.
GNU/Linux, come tutti i sistemi Unix, č in multiprogrammazione, ovvero multitasking, cioč in grado di eseguire diversi programmi, o processi elaborativi, contemporaneamente. Per poter realizzare questo, esiste un gestore dei processi elaborativi: Init, realizzato in pratica dall'eseguibile init, che viene avviato subito dopo l'attivazione del filesystem principale, e a sua volta si occupa di eseguire la procedura di inizializzazione del sistema. In pratica, esegue una serie di istruzioni necessarie alla configurazione corretta del sistema particolare che si sta avviando.
Molti servizi sono svolti da programmi che vengono avviati durante la fase di inizializzazione del sistema e quindi compiono silenziosamente la loro attivitŕ. Questi programmi sono detti demoni (daemon) e questo termine va considerato come equivalente a «servente» (server) o «esperto».
Nei sistemi Unix la gestione della rete č un elemento essenziale e normalmente presente. I servizi di rete vengono svolti da una serie di demoni attivati in fase di inizializzazione del sistema. Nei sistemi GNU/Linux, i servizi di rete sono controllati fondamentalmente da tre demoni:
inetd che si occupa di attivare di volta in volta, quando necessario, alcuni demoni che poi gestiscono servizi specifici;
tcpd che si occupa di controllare e filtrare l'utilizzazione dei servizi offerti dal proprio sistema contro gli accessi indesiderati;
rpc.portmap (oppure solo portmap) che si occupa del protocollo RPC (Remote Procedure Call).
Un servizio molto importante nelle reti locali consente di condividere porzioni di filesystem da e verso altri elaboratori connessi. Questo si ottiene con il protocollo NFS che permette quindi di realizzare dei filesystem di rete.
Tutti i sistemi operativi in multiprogrammazione (multitasking) hanno un sistema di coda di stampa (spool). GNU/Linux utilizza normalmente il demone lpd che in particolare č anche in grado di ricevere richieste di stampa remote, e a sua volta, di inviare richieste di stampa a elaboratori remoti.
I sistemi Unix, oltre che essere in multiprogrammazione sono anche multiutente, cioč possono essere usati da piů utenti contemporaneamente. La multiutenza dei sistemi Unix č da considerare nel modo piů ampio possibile, nel senso che si puň accedere all'utilizzo dell'elaboratore attraverso la console, terminali locali connessi attraverso porte seriali, terminali locali connessi attraverso una rete locale e terminali remoti connessi attraverso il modem.
In queste condizioni, il controllo dell'utilizzazione del sistema č essenziale. Per questo, ogni utente che accede deve essere stato registrato precedentemente, con un nome e una parola di accesso, o password.
La fase in cui un utente viene riconosciuto e quindi gli viene consentito di agire, č detta login. Cosě, la conclusione dell'attivitŕ da parte di un utente č detta logout.
Ciň che permette a un utente di interagire con un sistema operativo č la shell, che si occupa di interpretare ed eseguire i comandi dati dall'utente.
Dal punto di vista pratico, il funzionamento di un sistema Unix dipende molto dalla shell utilizzata, di conseguenza, la scelta della shell č molto importante. La shell standard del sistema GNU/Linux č Bash (il programma bash).
Una shell Unix normale svolge i compiti seguenti:
mostra l'invito, o prompt, all'inserimento dei comandi;
interpreta la riga di comando data dall'utente;
esegue delle sostituzioni, in base ai caratteri jolly e alle variabili di ambiente; *1*
mette a disposizione alcuni comandi interni;
mette in esecuzione i programmi;
gestisce la ridirezione dell'input e dell'output;
č in grado di interpretare ed eseguire dei file script di shell.
I comandi interni di una shell non bastano per svolgere tutte le attivitŕ di amministrazione del sistema. I programmi di utilitŕ sono quelli che di solito hanno piccole dimensioni, sono destinati a scopi specifici di amministrazione del sistema o anche solo di uso comune.
I programmi di utilitŕ di uso comune sono contenuti solitamente all'interno delle directory /bin/ e /usr/bin/. Quelli riservati all'uso da parte dell'amministratore del sistema, l'utente root, sono contenuti normalmente in /sbin/ e /usr/sbin/ dove la lettera «s» iniziale, sta per superuser, con un chiaro riferimento all'amministratore.
Tutti i sistemi operativi devono avere un mezzo per produrre del software. In particolare, Un sistema operativo Unix deve essere in grado di compilare programmi scritti in linguaggio C/C++. Gli strumenti di sviluppo del sistema GNU/Linux, composti da un compilatore in linguaggio C/C++ e da altri programmi di contorno, sono indispensabili per poter installare del software distribuito in forma sorgente non compilata.
Qualunque sistema operativo in multiprogrammazione, e tanto piů se anche multiutente, deve prevedere una procedura di arresto del sistema che si occupi di chiudere tutte le attivitŕ in corso prima di consentire lo spegnimento fisico dell'elaboratore.
GNU/Linux permette solo all'utente root di avviare la procedura di arresto del sistema con il comando seguente:
# shutdown -h now
In teoria, negli elaboratori i386 č possibile utilizzare la combinazione [Ctrl+Alt+Canc] per riavviare il sistema, ma č sempre preferibile richiamare esplicitamente la procedura di arresto del sistema, specificando che si vuole il riavvio finale.
# shutdown -r now
|
Generalmente, l'unico modo per un utente comune di spegnere il sistema, č quello di riavviare attraverso la combinazione di tasti [Ctrl+Alt+Canc]. Non č elegante, ma č il modo migliore per risolvere il problema. |
I vari componenti hardware di un elaboratore, sono rappresentati in un sistema Unix come file di dispositivo, contenuti normalmente nella directory /dev/ (device). Quando si vuole accedere direttamente a un dispositivo, lo si fa utilizzando il nome del file di dispositivo corrispondente.
Esistono due categorie fondamentali di dispositivi:
a carattere, cioč in grado di gestire i dati in blocchetti di un singolo byte per volta;
a blocchi, cioč in grado di gestire i dati solo in blocchi (settori) di una dimensione fissa.
Il tipico dispositivo a caratteri č la console o la porta seriale, mentre il tipico dispositivo a blocchi č un'unitŕ a disco. A titolo di esempio, la tabella 2.1 mostra l'elenco di alcuni nomi di dispositivo di GNU/Linux.
| dispositivo | descrizione |
| /dev/fd0 | la prima unitŕ a dischetti |
| /dev/fd0u1440 | unitŕ a dischetti con l'indicazione esplicita del formato: 1440 Kbyte |
| /dev/hda | il primo disco fisso IDE/EIDE |
| /dev/hda1 | la prima partizione del primo disco fisso IDE/EIDE |
| /dev/hdb | il secondo disco fisso IDE/EIDE |
| /dev/sda | il primo disco SCSI |
| /dev/sda1 | la prima partizione del primo disco SCSI |
| /dev/lp0 | la prima porta parallela dal punto di vista di GNU/Linux |
| /dev/lp1 | la seconda porta parallela dal punto di vista di GNU/Linux |
| /dev/ttyS0 | la prima porta seriale |
Alcuni file di dispositivo non fanno riferimento a componenti hardware veri e propri. Il piů noto di questi č /dev/null utilizzato come fonte per il «nulla» o come pattumiera senza fondo.
I nomi utilizzati per distinguere i file di dispositivo, sono stati scelti in base a qualche criterio mnemonico e all'uso piů frequente. Il punto č perň che non č detto che un dispositivo debba chiamarsi in un modo rispetto a un altro.
Sotto questo aspetto, le distribuzioni GNU/Linux non sono tutte uguali: ognuna interpreta in qualche modo questi nomi. Per fare un esempio, il dispositivo corrispondente all'unitŕ a dischetti da 1440 Kbyte, puň corrispondere a questi nomi differenti:
/dev/fd0H1440 per la distribuzione Red Hat;
/dev/fd0u1440 per le distribuzioni Slackware, Debian e SuSE (č anche la sigla indicata nei sorgenti del kernel).
Le cose si complicano ancora di piů quando si ha a che fare con sistemi Unix differenti. Quindi: attenzione.
Le unitŕ di memorizzazione a dischi sono dispositivi come gli altri, ma possono essere trattati in due modi diversi a seconda delle circostanze: i dischi, o le partizioni, possono essere visti come dei file enormi o come contenitori di file (filesystem).
Questa distinzione č importante perché capita spesso di utilizzare dischetti che non hanno alcuna struttura di dati essendo stati usati come se si trattasse di un unico file. Il caso piů comune č dato dai dischetti di avvio contenenti solo il kernel: non si tratta di dischetti all'interno dei quali č stato copiato il file del kernel, ma si tratta di dischetti che sono il kernel. *2*
La visione che normalmente si ha delle unitŕ di memorizzazione contenenti file e directory č un'astrazione gestita automaticamente dal sistema operativo. Questa astrazione si chiama filesystem.
Tutto ciň che č contenuto in un filesystem Unix č in forma di file: anche una directory č un file.
Quando si vuole fare riferimento a un file nel senso stretto del termine, ovvero un archivio di dati, se si vuole evitare qualunque ambiguitŕ si utilizza il termine file normale, o regular file.
Una directory č un file speciale contenente riferimenti ad altri file. I dati contenuti in un filesystem sono organizzati in forma gerarchica schematizzabile attraverso un grafo orientato (albero) che parte da una radice e si sviluppa in rami e nodi. La figura 2.2 mostra uno schema semplificato di un grafo orientato.
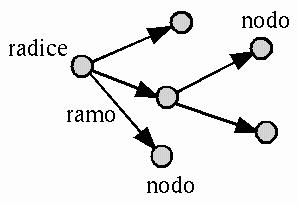
Figura 2.2:
Schema semplificato di un grafo orientato.
La radice č il nodo principale di questo grafo orientato, i rami rappresentano il collegamento (la discendenza) dei nodi successivi con quello di origine (il genitore). La radice corrisponde a una directory, mentre i nodi successivi possono essere directory, file di dati o file di altro genere.
Per identificare un nodo (file o directory), all'interno di questa gerarchia, si definisce il percorso (path). Il percorso č espresso da una sequenza di nomi di nodi che devono essere attraversati, separati da una barra obliqua (/). Il percorso idrogeno/carbonio/ossigeno rappresenta un attraversamento dei nodi idrogeno, carbonio e ossigeno.
Dal momento che il grafo di un sistema del genere ha un nodo di origine corrispondente alla radice, si distinguono due tipi di percorsi: relativo e assoluto.
Percorso relativo
Un percorso č relativo quando parte dalla posizione corrente (o attuale) del grafo per raggiungere la destinazione desiderata. Nel caso dell'esempio precedente, idrogeno/carbonio/ossigeno indica di attraversare il nodo idrogeno inteso come discendente della posizione corrente e quindi gli altri.
Percorso assoluto
Un percorso č assoluto quando parte dalla radice.
Il nodo della radice non ha un nome come gli altri: viene rappresentato con una sola barra obliqua (/), di conseguenza, un percorso che inizia con tale simbolo, č un percorso assoluto. Per esempio, /cloro/sodio indica un percorso assoluto che parte dalla radice per poi attraversare cloro e quindi raggiungere sodio.
Il grafo di un filesystem normale č orientato, nel senso che ha una direzione, ovvero ogni nodo ha un genitore e puň avere dei discendenti, e il nodo radice rappresenta l'origine. Quando in un percorso si vuole tornare indietro verso il nodo genitore, non si usa il nome di questo, ma un simbolo speciale rappresentato da due punti in sequenza (..). Per esempio, ../potassio rappresenta un percorso relativo in cui si raggiunge il nodo finale, potassio, passando prima per il nodo genitore della posizione corrente.
In alcuni casi, per evitare equivoci, puň essere utile poter identificare il nodo della posizione corrente. Il simbolo utilizzato č un punto singolo (.). Per cui, il percorso idrogeno/carbonio/ossigeno č esattamente uguale a ./idrogeno/carbonio/ossigeno.
Un grafo orientato, ovvero un albero, č tale quando esiste un solo percorso per unire due nodi di questo. Nei filesystem Unix non č necessariamente cosě. Infatti č possibile inserire dei collegamenti aggiuntivi, o link, che permettono l'utilizzo di percorsi alternativi. Si distinguono due tipi di questi collegamenti: simbolici e fisici (hard).
Collegamenti fisici, hard link
Un collegamento fisico, o hard link, č un collegamento che una volta creato ha lo stesso livello di importanza di quelli originali e non č distinguibile da quelli.
Collegamento simbolico, link simbolico, symlink
Il collegamento simbolico, o link simbolico, č un file speciale contenente un riferimento a un altro percorso e quindi a un altro nodo del grafo di directory e file.
In generale si preferisce l'uso di collegamenti simbolici per poter distinguere la realtŕ (o meglio l'origine) dalla finzione. Utilizzando un collegamento simbolico si dichiara apertamente che si sta indicando una scorciatoia e non si perde di vista il percorso originale.
In questo modo, il grafo della struttura di un filesystem Unix puň essere considerato molto simile a un grafo orientato, ovvero a un albero, con l'aggiunta di scorciatoie e percorsi alternativi rappresentati da questi collegamenti.
Non esiste una regola generale precisa che stabilisca quali siano i caratteri che possono essere usati per nominare un file. Esiste solo un modo per (cercare di) stare fuori dai guai: il simbolo / non deve essere utilizzato essendo il modo con cui si separano i nomi all'interno di un percorso; inoltre conviene limitarsi all'uso delle lettere dell'alfabeto inglese non accentate, dei numeri, del punto e del segno di sottolineatura.
Per convenzione, nei sistemi Unix i file che iniziano con un punto sono classificati come nascosti, e vengono mostrati e utilizzati solo quando sono richiesti espressamente.
|
Questi file, quelli che iniziano con un punto, sono nascosti per una buona ragione: si vuole evitare che utilizzando i caratteri jolly si faccia riferimento alla directory corrente ( |
I file di un filesystem Unix appartengono simultaneamente a un utente e a un gruppo di utenti. Per questo si parla di utente e gruppo proprietari, oppure semplicemente di proprietario e di gruppo.
L'utente proprietario puň modificare i permessi di accesso ai suoi file, limitando questi anche per se stesso. Si distinguono tre tipi di accesso: lettura, scrittura, esecuzione. Il significato del tipo di accesso dipende dal file cui questo si intende applicare.
Per i file normali:
l'accesso in lettura permette di leggerne il contenuto;
l'accesso in scrittura permette di modificarne il contenuto;
l'accesso in esecuzione permette di eseguirlo, se si tratta di un eseguibile binario o di uno script di qualunque tipo.
Per le directory:
l'accesso in lettura permette di leggerne il contenuto, e cioč di poter conoscere l'elenco dei file in esse contenuti (di qualunque tipo essi siano);
l'accesso in scrittura permette di modificarne il contenuto, ovvero di creare, eliminare e rinominare dei file;
l'accesso in esecuzione permette di attraversare una directory.
I permessi di un file permettono di attribuire privilegi differenti per gli utenti, a seconda che si tratti del proprietario del file, di utenti appartenenti al gruppo proprietario, oppure si tratti di utenti diversi. Cosě, per ogni file, un utente puň ricadere in una di queste tre categoria: proprietario, gruppo o utente diverso. *3*
I permessi si possono esprimere in due forme diverse: attraverso una stringa alfabetica o un numero.
I permessi possono essere rappresentati attraverso una stringa di nove caratteri in cui possono apparire le lettere r, w, x, oppure un trattino (-r indica un permesso in lettura, la lettera w indica un permesso in scrittura, la lettera x indica un permesso in esecuzione.
I primi tre caratteri della stringa rappresentano i privilegi concessi al proprietario stesso, il gruppetto di tre caratteri successivo rappresenta i privilegi degli utenti appartenenti al gruppo, il gruppetto finale di tre caratteri rappresenta i privilegi concessi agli altri utenti.
rw
-r--r--
L'utente proprietario puň accedervi in lettura e scrittura, mentre sia gli appartenenti al gruppo che gli altri utenti possono solo accedervi in lettura.
rwxr
-x---
L'utente proprietario puň accedervi in lettura, scrittura ed esecuzione; gli utenti appartenenti al gruppo possono accedervi in lettura e in esecuzione; gli altri utenti non possono accedervi in alcun modo.
rw
-------
L'utente proprietario puň accedervi in lettura e scrittura, mentre tutti gli altri non possono accedervi affatto.
I permessi possono essere rappresentati attraverso una serie di tre cifre numeriche, in cui la prima rappresenta i privilegi dell'utente proprietario, la seconda quelli del gruppo e la terza quelli degli altri utenti. Il permesso di lettura corrisponde al numero 4, il permesso di scrittura corrisponde al numero 2, il permesso di esecuzione corrisponde al numero 1. Il numero che rappresenta il permesso attribuito a un tipo di utente, si ottiene sommando i numeri corrispondenti ai privilegi che si vogliono concedere.
644
L'utente proprietario puň accedervi in lettura e scrittura (4+2), mentre sia gli appartenenti al gruppo che gli altri utenti possono solo accedervi in lettura.
750
L'utente proprietario puň accedervi in lettura, scrittura ed esecuzione (4+2+1); gli utenti appartenenti al gruppo possono accedervi in lettura e in esecuzione (4+1); gli altri utenti non possono accedervi in alcun modo.
600
L'utente proprietario puň accedervi in lettura e scrittura (4+2), mentre tutti gli altri non possono accedervi affatto.
I permessi dei file sono memorizzati in una sequenza di 9 bit, dove ogni gruppetto di tre rappresenta i permessi per una categoria di utenti (il proprietario, il gruppo, gli altri).
Assieme a questi 9 bit ne esistono altri tre, posti all'inizio, che permettono di indicare altrettante modalitŕ: SUID (Set User ID), SGID (Set Group ID) e Sticky (Save Text Image). Si tratta di attributi speciali che riguardano prevalentemente i file eseguibili. Solitamente non vengono usati e per lo piů gli utenti comuni ignorano che esistano.
Tutto questo serve adesso per sapere il motivo per il quale spesso i permessi espressi in forma numerica (ottale) sono di quattro cifre, con la prima che normalmente č azzerata (l'argomento verrŕ ripreso nel capitolo 53).
Per esempio, la modalitŕ 0644 rappresenta il permesso per l'utente proprietario di accedervi in lettura e scrittura e per gli altri utenti di accedervi in sola lettura.
L'indicazione della presenza di questi bit attivati puň essere vista anche nelle rappresentazioni in forma di stringa. L'elenco seguente mostra il numero ottale e la sigla corrispondente.
SUID = 4 = --s------
SGID = 2 = -----s---
Sticky = 1 = --------t
Come si puň osservare, questa indicazione prende il posto del permesso in esecuzione. Nel caso in cui il permesso in esecuzione corrispondente non sia attivato, la lettera (s o t) appare maiuscola.
Tra gli attributi di un file ci sono anche tre indicazioni data-orario:
la data e l'ora di creazione: viene modificata in particolare quando si cambia lo stato del file (permessi e proprietŕ), e si riferisce precisamente al cambiamento di inode (che verrŕ descritto piů avanti);
la data e l'ora di modifica: viene modificata quando si modifica il contenuto del file;
la data e l'ora di accesso: viene modificata quando si accede al file anche solo in lettura.
Una volta avviato un sistema Unix, prima che sia disponibile l'invito della shell, ovvero il prompt, occorre che l'utente sia riconosciuto dal sistema, attraverso la procedura di accesso (login). Quello che viene chiesto č l'inserimento del nome dell'utente (cosě come č stato registrato) e subito dopo la parola chiave (password) abbinata a quell'utente. Eccezionalmente puň trattarsi di un utente senza password, cosě come avviene per i mini sistemi a dischetti fatti per consentire le operazioni di manutenzione eccezionale.
Si distingue solo tra due tipi di utenti: l'amministratore, il cui nome č root, e gli altri utenti comuni. L'utente root non ha alcun limite di azione, gli altri utenti dipendono dai permessi attribuiti ai file (e alle directory) oltre che dai vincoli posti direttamente da alcuni programmi.
In teoria, č possibile usare un elaboratore personale solo utilizzando i privilegi dell'utente root. In pratica, questo non conviene perché si perde di vista il significato della gestione dei permessi sui file (e sulle directory) e soprattutto si rendono vani i sistemi di sicurezza predefiniti contro gli errori. Per comprendere meglio questo concetto, basta pensare a cosa succede in un sistema Dos quando si esegue un comando come quello seguente:
C:\> DEL *.*
Prima di iniziare la cancellazione, il Dos chiede una conferma ulteriore, proprio perché non esiste alcun tipo di controllo. In un sistema Unix, di solito ciň non avviene: la cancellazione inizia immediatamente senza richiesta di conferme. Se i permessi consentono la cancellazione dei file solo all'utente root, un utente registrato in modo diverso non puň fare alcun danno.
In conclusione, l'utente root deve stare molto attento a quello che fa proprio perché puň accedere a qualunque funzione o file del sistema, e il sistema non pone alcuna obbiezione al suo comportamento. Invece, un utente comune č vincolato dai permessi sui file e dai programmi che possono impedirgli di eseguire certe attivitŕ, di conseguenza, č possibile lavorare con meno attenzione.
Di solito, nelle distribuzioni GNU/Linux si trova il programma di utilitŕ adduser, oppure useradd, che consente all'utente root di aggiungere un nuovo utente. Il nome dell'utente non deve superare gli otto caratteri e tutti gli altri dati richiesti possono essere lasciati semplicemente al loro valore predefinito. Dopo la prima installazione del sistema GNU/Linux, č importante creare il proprio utente personale per poterlo usare senza i privilegi che ha l'amministratore.
La shell comprende solitamente il comando exit che ne termina l'esecuzione. Se si tratta di una shell avviata automaticamente subito dopo il l'accesso, il sistema provvederŕ ad avviare nuovamente la procedura di accesso.
Come giŕ č stato indicato, l'interpretazione dei comandi č compito della shell. L'interpretazione dei comandi implica la sostituzione di alcuni simboli che hanno un significato speciale.
Il glob (o globbing) č il metodo attraverso il quale, tramite un modello simbolico, č possibile indicare un gruppo di nomi di file. Corrisponde all'uso dei caratteri jolly del Dos, con la differenza fondamentale che č la shell a occuparsi della loro sostituzione, e non i programmi. Di solito, si possono utilizzare i simboli seguenti:
* |
l'asterisco rappresenta un gruppo qualsiasi di caratteri, compreso il punto, purché questo punto non si trovi all'inizio del nome;
? |
il punto interrogativo rappresenta un unico carattere qualsiasi, compreso il punto, purché questo punto non si trovi all'inizio del nome;
[...] |
le parentesi quadre permettono di rappresentare un carattere qualsiasi tra quelli contenuti al loro interno, o un intervallo di caratteri possibili.
Dal momento che č la shell a eseguire la sostituzione dei caratteri jolly, la sintassi tipica di un programma di utilitŕ č la seguente:
<programma> [<opzioni>] [<file>...] |
Nei sistemi Dos si usa spesso la convenzione inversa, secondo cui l'indicazione dei file avviene prima delle opzioni. Da un punto di vista puramente logico, potrebbe sembrare piů giusto l'approccio del Dos: si indica l'oggetto su cui agire e quindi si indica il modo. Facendo cosě si ottengono perň una serie di svantaggi:
ogni programma deve essere in grado di espandere i caratteri jolly per conto proprio;
non č possibile utilizzare l'espansione delle variabili di ambiente e nemmeno di altri tipi;
se si vogliono indicare elenchi di file che non possono essere espressi con i caratteri jolly, occorre che il programma sia in grado di gestire questa possibilitŕ, di solito attraverso la lettura di un file esterno.
In pratica, il tipo di semplificazione utilizzato dal Dos č poi la fonte di una serie di complicazioni per i programmatori e per gli utilizzatori.
Di solito, la shell si occupa di eseguire la sostituzione del carattere tilde (~). Nei sistemi Unix, ogni utente ha una directory personale, o directory home. Il simbolo ~ da solo viene sostituito dalla shell con la directory personale dell'utente che sta utilizzando il sistema, mentre un nominativo-utente preceduto dal simbolo ~, viene sostituito dalla shell con la directory personale dell'utente indicato.
Le variabili di ambiente sono gestite dalla shell e costituiscono uno dei modi attraverso cui si configura un sistema. I programmi possono leggere alcune variabili di loro interesse e modificare il proprio comportamento in base al loro contenuto.
Una riga di comando puň fare riferimento a una variabile di ambiente: la shell provvede a sostituirne l'indicazione con il suo contenuto.
I programmi, quando vengono eseguiti, hanno a disposizione alcuni canali standard per il flusso dei dati (input/output). Questi sono: standard input, standard output e standard error.
Standard input
Lo standard input viene utilizzato come fonte standard per i dati in ingresso (input) nel programma.
Standard output
Lo standard output viene utilizzato come destinazione standard per i dati in uscita (output) dal programma.
Standard error
Lo standard error, viene utilizzato come destinazione standard per i dati in uscita dal programma derivati da situazioni anomale.
Lo standard input č rappresentato di norma dai dati provenienti dalla tastiera del terminale. Lo standard output e lo standard error sono emessi normalmente attraverso lo schermo del terminale.
Per mezzo della shell si possono eseguire delle ridirezioni di questi flussi di dati, per esempio facendo in modo che lo standard output di un programma sia inserito come standard input di un altro, creando cosě una pipeline.
<programma> < <file-di-dati> |
Si ridirige lo standard input utilizzando il simbolo minore (<) seguito dalla fonte alternativa di dati. Il programma a sinistra del simbolo < riceve come standard input il contenuto del file indicato a destra.
$ sort < elenco.txt
Visualizza il contenuto del file elenco.txt dopo averlo riordinato.
<programma> > <file-di-dati> |
Si ridirige lo standard output utilizzando il simbolo maggiore (>) seguito dalla destinazione alternativa dei dati. Il programma a sinistra del simbolo > emette il suo standard output all'interno del file indicato a destra che viene creato per l'occasione.
Lo standard output puň essere aggiunto a un file preesistente; in tal caso si utilizza il simbolo >>.
$ ls > elenco.txt
Genera il file elenco.txt con il risultato dell'esecuzione di ls.
$ ls >> elenco.txt
Aggiunge al file elenco.txt il risultato dell'esecuzione di ls.
<programma> 2> <file-di-dati> |
Si ridirige lo standard error utilizzando il simbolo 2> seguito dalla destinazione alternativa dei dati. Il programma a sinistra del simbolo 2> emette il suo standard error all'interno del file indicato a destra che viene creato per l'occasione.
Lo standard error puň essere aggiunto a un file preesistente; in tal caso si utilizza il simbolo 2>>.
$ controlla 2> errori.txt
Genera il file errori.txt con il risultato dell'esecuzione dell'ipotetico programma controlla.
$ controlla 2>> errori.txt
Aggiunge al file errori.txt il risultato dell'esecuzione dell'ipotetico programma controlla.
<programma1> | <programma2> [ | <programma3>...] |
Si ridirige lo standard output di un programma nello standard input di un altro, utilizzando il simbolo barra verticale (|). Il programma a sinistra del simbolo | emette il suo standard output nello standard input di quello che sta a destra.
|
Nella rappresentazione schematica delle sintassi dei programmi, questo simbolo ha normalmente il significato di una scelta alternativa tra opzioni diverse, parole chiave o altri argomenti. In questo caso fa proprio parte della costruzione di una pipeline. |
$ ls | sort
Riordina il risultato del comando ls.
$ ls | sort | less
Riordina il risultato del comando ls e quindi lo fa scorrere sullo schermo con l'aiuto del programma less.
In linea di principio, con il termine comando ci si dovrebbe riferire ai comandi interni di una shell, mentre con il termine utilitŕ (utility), o programma (di utilitŕ), si dovrebbe fare riferimento a programmi eseguibili esterni alla shell. Di fatto perň, dal momento che si mette in esecuzione un programma impartendo un comando alla shell, con questo termine si fa spesso riferimento in maniera indistinta a comandi interni di shell o (in mancanza) a comandi esterni o utilitŕ.
Naturalmente, questo ragionamento vale fino a quando si tratta di programmi di utilitŕ di uso comune, non troppo complessi, che usano un sistema di input/output elementare. Sarebbe un po' difficile definire comando un programma di scrittura o un navigatore di Internet.
La sintassi di un programma o di un comando segue delle regole molto semplici.
Le <metavariabili>, scritte in questo modo, descrivono l'informazione che deve essere inserita al loro posto.
Le altre parole rappresentano dei termini chiave che, se usati, devono essere indicati cosě come appaiono nello schema sintattico.
Quello che appare racchiuso tra parentesi quadre rappresenta una scelta facoltativa: puň essere utilizzato o meno.
La barra verticale (|) rappresenta la possibilitŕ di scelta tra due possibilitŕ alternative: quello che sta alla sua sinistra e quello che sta alla sua destra. Per esempio, uno | due rappresenta la possibilitŕ di scegliere una tra le parole uno e due.
Quello che appare racchiuso tra parentesi graffe rappresenta una scelta obbligatoria e serve in particolare per evitare equivoci nell'interpretazione quando si hanno piů scelte alternative, separate attraverso il simbolo |. Seguono alcuni esempi.
{uno | due | tre}
|
Rappresenta la scelta obbligatoria di una tra le tre parole chiave: uno, due e tre.
{
|
Rappresenta la scelta obbligatoria di una tra due opzioni equivalenti.
I puntini di sospensione rappresentano la possibilitŕ di aggiungere altri elementi dello stesso tipo di quello che li precede. Per esempio, <file>... rappresenta la metavariabile file che puň essere seguita da altri valori dello stesso tipo rappresentato dalla metavariabile stessa.
Naturalmente, puň capitare che i simboli utilizzati per rappresentare la sintassi, servano negli argomenti di un comando o di un programma. I casi piů evidenti sono:
le pipeline che utilizzano la barra verticale per indicare il flusso di dati tra un programma e il successivo;
le parentesi graffe usate dalla shell Bash come tipo particolare di espansione.
Quando ciň accade, occorre fare attenzione al contesto per poter interpretare correttamente il significato di una sintassi, osservando gli esempi eventualmente proposti.
Il programma di utilitŕ tipico ha la sintassi seguente:
programma [<opzioni>] [<file>...] |
In questo caso, il nome del programma č proprio programma.
Normalmente vengono accettate una o piů opzioni facoltative, espresse attraverso una lettera dell'alfabeto preceduta da un trattino (-a-b
programma -a -b
č traducibile nel comando seguente:
programma -ab
I programmi piů recenti includono opzioni descrittive formate da un nome preceduto da due trattini. In presenza di questi tipi di opzioni, non si possono fare aggregazioni nel modo appena visto.
A volte si incontrano opzioni che richiedono l'indicazione aggiuntiva di un altro argomento.
La maggior parte dei programmi di utilitŕ esegue delle elaborazioni su file, generando un risultato che viene emesso normalmente attraverso lo standard output. Spesso, quando non vengono indicati file negli argomenti, l'input per l'elaborazione viene ottenuto dallo standard input.
Alcuni programmi permettono l'utilizzo del trattino (-
In generale, quando si usa il termine «programma» non č detto necessariamente quale sia la sua estensione reale. Si puň usare questo termine per identificare qualcosa che si compone di un solo file eseguibile, oppure un piccolo sistema composto da piů componenti, che vengono comandate da un solo sistema frontale.
Spesso, e in particolare all'interno di questo documento, quando si vuole fare riferimento a un programma inteso come un insieme di componenti, oppure come qualcosa di astratto per il quale nel contesto non conta il modo in cui viene avviato, lo si indica con un nome che non ha enfatizzazioni particolari, e generalmente ha l'iniziale maiuscola. Per esempio, questo č il caso della shell Bash, a cui si č accennato, il cui eseguibile č in realtŕ bash.
Per evitare ambiguitŕ, quando si vuole essere certi di fare riferimento a un programma eseguibile, si specifica proprio che si tratta di questo, cioč di un «eseguibile», e per mostrarlo si possono utilizzare enfatizzazioni di tipo dattilografico, e soprattutto si scrive il nome esattamente nel modo in cui ciň va fatto per avviarlo.
Nelle sezioni seguenti vengono descritti in modo sommario alcuni programmi di utilitŕ fondamentali. Gli esempi mostrati fanno riferimento all'uso della shell Bash che costituisce attualmente lo standard per GNU/Linux.
Č importante ricordare che negli esempi viene mostrato un invito differente a seconda che ci si riferisca a un comando impartito da parte di un utente comune o da parte dell'amministratore: il dollaro ($) rappresenta un'azione di un utente comune, mentre il simbolo # rappresenta un'azione dell'utente root.
Chi lo desidera, puň dare un'occhiata alla tabella 2.2, alla fine del capitolo, per farsi un'idea dei comandi del sistema GNU/Linux attraverso un abbinamento con il Dos.
ls [<opzioni>] [<file>...] |
Elenca i file contenuti in una directory.
$ ls
Elenca il contenuto della directory corrente.
$ ls -l *.doc
Elenca tutti i file che terminano con il suffisso .doc che si trovano nella directory corrente. L'elenco contiene piů dettagli sui file essendoci l'opzione -l
cd [<directory>] |
Cambia la directory corrente.
$ cd /tmp
Cambia la directory corrente, facendola diventare /tmp/.
$ cd ciao
Cambia la directory corrente, spostandosi nella directory ciao/ che discende da quella corrente.
$ cd ~
Cambia la directory corrente, spostandosi nella directory personale (home) dell'utente.
$ cd ~daniele
Cambia la directory corrente, spostandosi nella directory personale dell'utente daniele.
mkdir [<opzioni>] <directory>... |
Crea una directory.
$ mkdir cloro
Crea la directory cloro/, come discendente di quella corrente.
$ mkdir /sodio/cloro
Crea la directory cloro/, come discendente di /sodio/.
$ mkdir ~/cloro
Crea la directory cloro/, come discendente della directory personale dell'utente attuale.
cp [<opzioni>] <origine>... <destinazione> |
Copia uno o piů file (incluse le directory) in un'unica destinazione.
|
La copia in un sistema Unix non funziona come nei sistemi Dos, e ciň principalmente a causa di due fattori: i caratteri jolly (ovvero il file globbing) vengono risolti dalla shell prima dell'esecuzione del comando e i filesystem Unix possono utilizzare i collegamenti simbolici. |
Se vengono specificati solo i nomi di due file normali, il primo viene copiato sul secondo, viene cioč generata una copia che ha il nome indicato come destinazione. Se il secondo nome indicato č una directory, il file viene copiato nella directory con lo stesso nome di origine. Se vengono indicati piů file, l'ultimo nome deve essere una directory e verranno generate le copie di tutti i file indicati, all'interno della directory di destinazione. Di conseguenza, quando si utilizzano i caratteri jolly, la destinazione deve essere una directory. In mancanza di altre indicazioni attraverso l'uso di opzioni adeguate, le directory non vengono copiate.
|
Chi utilizzava il Dos potrebbe essere abituato a usare il comando |
I file elencati nell'origine potrebbero essere in realtŕ dei collegamenti simbolici. Se non viene specificato diversamente attraverso l'uso delle opzioni, questi vengono copiati cosě come se fossero file normali; cioč la copia sarŕ ottenuta a partire dai file originali e non si otterrŕ quindi una copia dei collegamenti.
|
Equivalente a -dpR
|
Copia i collegamenti simbolici mantenendoli come tali, invece di copiare il file a cui i collegamenti si riferiscono.
|
Sovrascrittura forzata dei file di destinazione.
|
Crea un collegamento fisico invece di copiare i file.
|
Mantiene le proprietŕ e i permessi originali.
|
Copia file e directory in modo ricorsivo (includendo le sottodirectory), considerando tutto ciň che non č una directory come un file normale.
|
Copia file e directory in modo ricorsivo (includendo le sottodirectory).
$ cp -r /test/* ~/prova
Copia il contenuto della directory /test/ in ~/prova/ copiando anche eventuali sottodirectory contenute in /test/.
|
Se |
$ cp -r /test ~/prova
Copia la directory /test/ in ~/prova/ (attaccando test/ a ~/prova/) copiando anche eventuali sottodirectory contenute in /test/.
$ cp -dpR /test ~/prova
Copia la directory /test/ in ~/prova/ (attaccando test/ a ~/prova/) copiando anche eventuali sottodirectory contenute in /test/, mantenendo inalterati i permessi e riproducendo i collegamenti simbolici eventuali.
ln [<opzioni>] <origine>... <destinazione> |
Crea uno o piů collegamenti di file (incluse le directory) in un'unica destinazione.
|
La creazione di un collegamento č un'azione simile a quella della copia. Di conseguenza valgono le stesse considerazioni fatte in occasione del comando |
Se vengono specificati solo i nomi di due file normali, il secondo diventa il collegamento del primo. Se il secondo nome indicato č una directory, al suo interno verranno creati altrettanti collegamenti quanti sono i file e le directory indicati come origine. I nomi utilizzati saranno gli stessi di quelli di origine. Se vengono indicati piů file, l'ultimo nome deve corrispondere a una directory.
Č ammissibile la creazione di collegamenti che fanno riferimento ad altri collegamenti.
Se ne possono creare di due tipi: collegamenti fisici e collegamenti simbolici. Questi ultimi sono da preferire (a meno che ci siano delle buone ragioni per utilizzare dei collegamenti fisici). Se non viene richiesto diversamente attraverso le opzioni, si generano dei collegamenti fisici invece che i consueti collegamenti simbolici.
|
Crea un collegamento simbolico.
|
Sovrascrittura forzata dei file o dei collegamenti giŕ esistenti nella destinazione.
$ ln -s /test/* ~/prova
Crea, nella destinazione ~/prova/, una serie di collegamenti simbolici corrispondenti a tutti i file e a tutte le directory che si trovano all'interno di /test/.
$ ln -s /test ~/prova
Crea, nella destinazione ~/prova, un collegamento simbolico corrispondente al file o alla directory /test. Se ~/prova č una directory, viene creato il collegamento ~/prova/test; se ~/prova non esiste, viene creato il collegamento ~/prova.
rm [<opzioni>] <nome>... |
Rimuove i file indicati come argomento. In mancanza dell'indicazione delle opzioni necessarie, non vengono rimosse le directory.
|
Rimuove il contenuto delle directory in modo ricorsivo.
$ rm prova
Elimina il file prova.
$ rm ./-r
Elimina il file -r che inizia il suo nome con un trattino, senza confondersi con l'opzione -r
$ rm -r ~/varie
Elimina la directory varie/ che risiede nella directory personale, insieme a tutte le sue sottodirectory eventuali.
# rm -r .*
Elimina tutti i file e le directory a partire dalla directory radice! In pratica elimina tutto.
Questo č un errore tipico di chi vuole cancellare tutte le directory nascoste (cioč quelle che iniziano con un punto) contenute nella directory corrente. Il disastro avviene perché nei sistemi Unix, .* rappresenta anche la directory corrente (.) e la directory precedente o genitrice (..).
mv [<opzioni>] <origine>... <destinazione> |
Sposta i file e le directory. Se vengono specificati solo i nomi di due elementi (file o directory), il primo viene spostato e rinominato in modo da ottenere quanto indicato come destinazione. Se vengono indicati piů elementi (file o directory), l'ultimo attributo deve essere una directory: verranno spostati tutti gli elementi elencati nella directory di destinazione. Nel caso di spostamenti attraverso filesystem differenti, vengono spostati solo i cosiddetti file normali (quindi: niente collegamenti e niente directory).
|
Nei sistemi Unix non esiste la possibilitŕ di rinominare un file o una directory semplicemente come avviene nel Dos. Per cambiare un nome occorre spostarlo. Questo fatto ha poi delle implicazioni nella gestione dei permessi delle directory. |
$ mv prova prova1
Cambia il nome del file (o della directory) prova in prova1.
$ mv * /tmp
sposta, all'interno di /tmp/, tutti i file e le directory che si trovano nella directory corrente.
cat [<opzioni>] [<file>...] |
Concatena dei file e ne emette il contenuto attraverso lo standard output. Il comando emette di seguito i file indicati come argomento attraverso lo standard output (sullo schermo), in pratica qualcosa di simile al comando TYPE del Dos. Se non viene fornito il nome di alcun file, viene utilizzato lo standard input.
$ cat prova prova1
Mostra di seguito il contenuto di prova e prova1.
$ cat prova prova1 > prova2
Genera il file prova2 come risultato del concatenamento in sequenza di prova e prova1.
In questa sezione vengono descritti brevemente alcuni termini che fanno parte del linguaggio comune degli ambienti Unix. L'elenco non č esauriente; č inteso solo come aiuto al principiante.
Il termine account rappresenta letteralmente un conto, come quello che si puň avere in banca. All'interno di un sistema operativo Unix, si ha un account quando si č stati registrati (e di conseguenza č stato ottenuto un UID) ed č possibile accedere attraverso la procedura di accesso.
Case sensitive, case insensitive
Con queste due definizioni si intende riferirsi rispettivamente alla «sensibilitŕ» o meno verso la differenza tra le lettere maiuscole e minuscole. Generalmente, i sistemi Unix sono sensibili a questa differenza, ma esistono circostanze in cui questa non c'č o si vuole ignorare.
Negli ambienti Unix, core č sinonimo di memoria centrale, o RAM. Questa parola deriva dal fatto che le prime forme di memoria centrale erano realizzate da un reticolo di nuclei ferromagnetici: la memoria a nuclei, ovvero core. Per questo motivo, spesso, quando un processo termina in modo anormale, il sistema operativo scarica in un file l'immagine che questo processo aveva in memoria. Questo file ha il nome core (ovviamente), e puň essere analizzato successivamente attraverso strumenti diagnostici opportuni.
Il daemon, o demone, č un programma che funziona sullo sfondo (background) e compie dei servizi in modo ripetitivo, come in un circolo vizioso. Questo termine č tipico degli ambienti Unix, mentre con altri sistemi operativi si utilizzano altre definizioni, per esempio server. Per tradizione, la maggior parte dei programmi demone ha un nome che termina con la lettera «d».
Normalmente, con il termine «dominio» si intende fare riferimento al nome che ha un certo nodo di rete in una rete Internet. Questo nome č composto da vari elementi, che servono a rappresentare una gerarchia di domini, in modo simile a ciň che si fa nei filesystem con la struttura delle directory. Un «nome di dominio» puň rappresentare una posizione intermedia di questa gerarchia, oppure anche il nome completo di un nodo.
L'espressione regolare (si veda il capitolo 154) č un modo per definire la ricerca di stringhe attraverso un modello. Viene usata da diversi programmi di utilitŕ.
Il filesystem nativo del sistema GNU/Linux č il tipo Ext2, o Second-extended.
File Allocation Table. La FAT č una parte componente del filesystem dei sistemi Dos. Č cosě particolare che questo tipo di filesystem viene chiamato con questa stessa sigla: FAT.
Group ID o numero identificativo del gruppo di utenti.
Glob, globbing, caratteri jolly
Quando si vuole identificare un gruppo di file (e directory) attraverso una sola definizione si utilizza il meccanismo del glob, corrispondente in ambiente Dos all'uso dei caratteri jolly. Si tratta di solito dell'asterisco, del punto interrogativo e delle parentesi quadre.
Host č l'oste, ovvero, colui che ospita. Il termine host viene usato nell'ambito delle connessioni in rete per definire i nodi, ovvero le stazioni che la compongono, dato che generalmente (anche se non necessariamente) questi sono degli elaboratori che svolgono e ospitano qualche tipo di servizio.
Il verbo «implementare» viene usato comunemente in ambito informatico come traduzione del verbo inglese to implement. In questo contesto rappresenta il modo con cui una caratteristica progettuale particolare, č stata definita in pratica in un determinato sistema. In altre parole, l'implementazione č la soluzione pratica adottata per assolvere a una determinata funzione, soprattutto quando le indicazioni originarie per raggiungere il risultato erano incomplete. In forma ancora piů stringata, l'implementazione č la realizzazione di qualcosa in un determinato contesto.
Internazionalizzazione, i18n
L'internazionalizzazione č l'azione con cui si realizza o si modifica un programma, in modo che sia sensibile alla «localizzazione».
Il termine job viene usato spesso nella documentazione Unix in riferimento a compiti di vario tipo, a seconda del contesto.
Job di shell
Le shell POSIX, e in particolare Bash, sono in grado di gestire i job di shell che rappresentano un insieme di processi generati da un singolo comando.
Job di stampa
Si tratta di stampe accodate nella coda di stampa (spool).
Job di scheduling
Si tratta di comandi la cui esecuzione č stata pianificata per un certo orario o accodata in attesa di risorse disponibili.
Le situazioni in cui il termine job viene adoperato possono essere anche altre, ma gli esempi indicati bastano per intendere l'ampiezza del significato.
Localizzazione, l10n
La localizzazione č la configurazione attraverso la quale si fa in modo che un determinato programma si comporti in modo adatto alle particolaritŕ linguistico-nazionali locali.
Log, registrazioni
In informatica, il log equivale al giornale di bordo delle navi. Il log č quindi un sistema automatico di registrazione di avvenimenti significativi. I file che contengono queste annotazioni sono detti file di log, e potrebbero essere identificati anche come i file delle registrazioni. In generale, il log č un registro, e le annotazioni che vi si fanno sono delle registrazioni.
Mount, unmount, montaggio, smontaggio
Nei sistemi operativi Unix, quando si vuole accedere ai dati memorizzati su disco, non si puň fare riferimento a un file appartenente a una certa unitŕ come avviene nei sistemi Dos e derivati. Si deve sempre fare riferimento al filesystem globale. Per fare questo, tutti i dischi a cui si vuole accedere devono essere collegati tramite un procedimento simile all'innesto di rami. Il termine montaggio, o mount, indica un collegamento, o l'innesto, del contenuto di un disco nel filesystem globale; il termine smontaggio, o unmount, indica lo scollegamento o il distacco di un disco dalla struttura globale.
Questa sigla č acronimo di Max Transfer Unit e definisce la dimensione massima in byte delle trame (frame) che possono essere inviate nella rete attraverso una certa interfaccia.
Con questo termine si vorrebbe fare riferimento al codice necessario per indicare la fine di una riga di testo e l'inizio di quella successiva. Utilizzando questo nome si dovrebbe evitare di fare riferimento in modo diretto al codice effettivo in modo che il concetto possa essere adatto a diversi sistemi.
GNU/Linux, come tutti i sistemi tradizionali della famiglia Unix, utilizza il codice <LF>. Nei sistemi Dos e discendenti si utilizza invece la coppia <CR><LF>, per cui, se si tenta di stampare un testo fatto per i sistemi Unix utilizzando una stampante configurata per operare con il sistema operativo Dos, come risultato si otterranno una serie di righe scalettate.
Per ovviare all'inconveniente, tenendo conto che raramente una stampante del genere puň essere configurata per andare a capo con il solo codice <LF>, č possibile utilizzare un filtro che trasformi il carattere <LF> in <CR><LF>. Il programma filtro č abbastanza noto e si chiama unix2dos.
|
Spesso, negli ambienti Unix si confonde tranquillamente il termine newline con il codice <LF>. Questo costituisce un problema, perché ci sono situazioni in cui č importante chiarire che si tratta del codice <LF> in modo indipendente dalla piattaforma a cui si applica il concetto. Per questo, quando si incontra questo termine, č indispensabile fare attenzione al senso del testo, usando un po' di buon senso. |
Un servizio molto importante nelle reti locali č dato dalla possibilitŕ di condividere porzioni di filesystem da e verso altri elaboratori connessi. Questo servizio si ottiene con il protocollo NFS e consente quindi la condivisione di dati attraverso la rete.
NFS viene indicato spesso come acronimo di Network File System e in alcuni casi di Network File Sharing. Le due possibili interpretazioni rappresentano due aspetti della stessa cosa: l'utilizzo di un filesystem che si estende attraverso la rete e la condivisione dei dati che ne deriva.
Network News Transfer Protocol. Si tratta del protocollo che si occupa di trasmettere i messaggi news. Un server NNTP č un elaboratore che si occupa di raccogliere una copia dei messaggi news dei gruppi di discussione e di consentire agli utenti di leggere e inviare messaggi all'interno di questi.
Password, passphrase
Si riferisce a una parola o a una frase utilizzata come mezzo di verifica dell'identificazione per poter accedere a un servizio di qualunque genere. Puň apparire tradotta in vari modi; tuttavia, la traduzione piů probabile č «parola di accesso» e «frase di accesso».
Process ID o numero identificativo del processo.
Pipe, pipeline *4*
Si tratta di una tubazione immaginaria attraverso la quale si convoglia l'output di un programma verso l'input di un altro. La connessione di piů programmi in questo modo č compito della shell e di solito si utilizza il simbolo | per indicare questa operazione. Per lo stesso motivo, quando il contesto lo consente, il simbolo | viene anche chiamato pipe.
Il termine proxy viene usato in informatica in varie circostanze per identificare un servizio che si comporta in qualche modo come un procuratore, o un procacciatore di qualcosa. Il classico esempio di proxy č il server che si inserisce tra una rete locale e una rete esterna, allo scopo di eseguire gli accessi verso la rete esterna per conto dei nodi della rete locale, senza che questi possano avere alcun contatto diretto con l'esterno. Di solito, questo tipo di proxy incorpora una memoria cache per ridurre gli accessi ripetuti alle stesse risorse esterne. Tuttavia č bene tenere a mente che questa definizione si usa anche per altri tipi di servizi meno appariscenti.
Il record č in generale una registrazione di qualunque genere. In informatica, il record corrisponde di solito a una riga di un file di dati. Un record č normalmente suddiviso in campi, o field, per cui si puň fare un'analogia con un archivio a schede: l'archivio č il file, le schede sono i record, e i campi sono i vari elementi indicati nelle schede.
Nei sistemi operativi della famiglia Unix, quando si parla di file, si intendono anche le directory oltre che altri oggetti con funzioni specifiche. Per specificare che si parla di un file puro e semplice, comprendendo in questa categoria anche gli eseguibili, si parla di regular file o di file normale.
Run level, livello di esecuzione
Quando si utilizza una procedura di inizializzazione del sistema in stile System V, che č poi quella normale, si distinguono diversi livelli di esecuzione, in modo da poter definire quali parti del sistema devono essere attivate e quali no, a seconda delle esigenze.
Il livello di esecuzione č un numero positivo che parte da zero, il cui significato dipende dal modo in cui il sistema č configurato. Di solito il livello 0 č riservato per la fase di preparazione allo spegnimento, il livello 1 č riservato al funzionamento monoutente e il livello 6 č riservato alla fase di preparazione al riavvio del sistema.
Uno script č un file di comandi che costituisce in pratica un programma interpretato. Normalmente, l'interprete di uno script č anche una shell.
Shell
La shell di un sistema operativo č quel programma che si occupa di interpretare ed eseguire i comandi dati dall'utente, attraverso una riga di comando. Il termine shell, utilizzato per questo scopo, nasce proprio dai sistemi operativi Unix.
Send Mail Transfer Protocol. Si tratta del protocollo che si occupa di trasmettere la posta elettronica. Un server SMTP č un elaboratore che si occupa di gestire la posta elettronica di un certo gruppo di utenti i quali utilizzano quell'elaboratore come loro centrale di smistamento dei messaggi.
Il file o il dispositivo predefinito per l'emissione dei dati relativi a segnalazioni di errore č lo standard error. Di solito si tratta del video della console o del terminale da cui si opera. Lo standard error, di norma, puň essere ridiretto utilizzando il simbolo 2> seguito dal nome del file o del dispositivo da utilizzare.
Il file o il dispositivo predefinito per l'inserimento dei dati, č lo standard input. Di solito č la tastiera della console o del terminale da cui si opera. Per terminare l'inserimento occorre fornire il carattere di fine file (^D) che di solito si ottiene con la combinazione [Ctrl+d].
Lo standard input, di norma, puň essere ridiretto utilizzando il simbolo minore (<) seguito dal nome del file o del dispositivo da utilizzare, oppure utilizzando il simbolo pipe (|) quando si vuole utilizzare l'output di un comando come input per il comando successivo.
Il file o il dispositivo predefinito per l'uscita dei dati, č lo standard output. Di solito č il video della console o del terminale da cui si opera. Lo standard output, di norma, puň essere ridiretto utilizzando il simbolo maggiore (>) seguito dal nome del file o del dispositivo da utilizzare, oppure puň essere diretto a un comando seguente attraverso il simbolo pipe (|).
Alle origini, il modo normale per interagire con un elaboratore era l'uso della telescrivente: teletype. Da questo nome deriva la sigla TTY usata normalmente per identificare un terminale generico. La console č il terminale principale che fa parte dell'elaboratore stesso. Quando si parla di terminale si intende attualmente un complesso formato da una tastiera e un da video.
Quando si parla di un flusso di dati proveniente da un terminale, come nel caso dello standard input, si fa riferimento a quanto inserito tramite la tastiera. Quando si parla di un flusso di dati verso un terminale, come nel caso dello standard output, si fa riferimento a quanto viene emesso sullo schermo.
User ID o numero identificativo dell'utente.
UNIX domain socket, socket di dominio UNIX
Si tratta di un sistema di comunicazione tra le applicazioni basato su un tipo di file speciale: il socket. Alcuni demoni offrono servizi attraverso questo tipo di comunicazione stando in ascolto in attesa di una richiesta di connessione da parte delle applicazioni client.
Uniform Resource Locator, Uniform Resource Identifier. Č il modo con cui si definisce un indirizzo che identifica precisamente una risorsa di rete, come una pagina HTML, un file in un servizio FTP, e altro ancora.
Utility, utilitŕ, programma di utilitŕ
Un'utility, ovvero un programma di utilitŕ, č un programma utile e pratico, che svolge il suo compito senza tanti fronzoli e senza essere troppo appariscente. Di solito, i programmi di questo tipo sono quelli che fanno parte integrante del sistema operativo.
| Dos | GNU/Linux |
| DIR | ls -l |
| DIR /W | ls |
| MD PIPPO | mkdir pippo |
| CD PIPPO | cd pippo |
| RD PIPPO | rmdir pippo |
| COPY *.* \PROVA | cp * /prova |
| XCOPY *.* \PROVA /E /S | cp -dpR * /prova |
| REN ARTICOLO LETTERA | mv articolo lettera |
| MOVE *.* \PROVA | mv * /prova |
| DEL ARTICOLO | rm articolo |
| DELTREE TEMP | rm -R temp |
| TYPE LETTERA | cat lettera |
| TYPE LETTERA | MORE | cat lettera | more |
| HELP DIR | man ls |
| FORMAT A: /N:18 /T:80 | fdformat /dev/fd0u1440 |
| FORMAT A: /N:9 /T:80 | fdformat /dev/fd0u720 |
| DISKCOPY A: B: | cp /dev/fd0 /dev/fd1 |
| DISKCOPY A: A: | cp /dev/fd0 /tmp/pippo ; cp /tmp/pippo /dev/fd0 |
| KEYB IT | loadkeys it |
| CLS | clear |
| BACKUP C:\DATI\*.* A: /S | tar cvf /dev/fd0 -L 1440 -M /dati |
| FIND "saluti" PRIMO.DOC | grep "saluti" primo.doc |
| FOR %A IN (*.DOC) DO FIND "saluti" %A | grep "saluti" *.doc |
| MEM | free |
---------------------------
Appunti Linux 1999.09.21 --- Copyright © 1997-1999 Daniele Giacomini -- daniele @ pluto.linux.it
1.) La sostituzione dei caratteri jolly, ovvero dei metacaratteri, č il procedimento attraverso il quale alcuni caratteri speciali vengono tradotti in un elenco di nomi di file e directory corrispondenti. Negli ambienti Unix si utilizza il termine globbing per fare riferimento a questo concetto.
2.) Č anche possibile avere dischetti di avvio organizzati normalmente con un filesystem, ma questo particolare tipo di dischetti di avvio viene descritto piů avanti.
3.) Per gruppo proprietario si intende quello dell'utente proprietario.
4.) Queste parole si pronunciano: « p a i p » e « p a i p l a i n ».